キーワード: レザバーコンピューティング、神経修飾機構、物理実装、エッジAI
[ 発表者 ]
- 酒見 悠介 (千葉工業大学 数理工学研究センター 上席研究員/東京大学国際高等研究所ニューロインテリジェンス国際研究機構(WPI-IRCN) 連携研究者)
- 信川 創 (千葉工業大学 情報科学部 教授)
- 松木 俊貴 (防衛大学校 情報工学科 助教)
- 森江 隆 (九州工業大学 大学院生命体工学研究科 特任教授・名誉教授)
- 合原 一幸 (東京大学 特別教授・名誉教授/東京大学国際高等研究所ニューロインテリジェンス国際研究機構(WPI-IRCN) 副機構長・主任研究者/千葉工業大学 数理工学研究センター 主席研究員)
[ 概要 ]
酒見悠介 (千葉工大)、信川創 (千葉工大)、松木俊貴(防衛大)、森江隆 (九工大)、合原一幸 (東大)は、次世代型人工知能であるレザバーコンピューティング(RC)※1に、脳の神経修飾機構を模した自己制御機能を付与する拡張を行いました。この新しい人工知能モデルは自己制御型レザバーコンピューティング(Self-modulated RC: SM-RC)と名付けられました。数値シミュレーションにより、SM-RCは、従来のRCでは不可能であった、注意機構やカオスダイナミクスの活用が実現できることを示しました。さらに、SM-RCは、従来のRCと比べて、極めて高い時系列予測性能を持つことを明らかにしました。SM-RCは高い学習性能と、電力効率の鍵となる物理実装性※2とを両立しているため、エッジAIへの応用が期待されます。この成果は、2024年1月12日に査読付き国際学術雑誌「Communications Physics」で公開されました。
■背景
深層学習を中心とした人工知能(AI)技術は社会を大きく変革しつつありますが、多くのAIは莫大な電力を必要とするために、センサーや、ロボットへの搭載は未だ困難です。AIに必要な電力を大きく削減することができれば、ロボットなどのよりユーザーに近いところでのAI動作(エッジAI)が可能になり、社会の隅々までAIによる自動化・高性能化の恩恵をもたらすことができます。
レザバーコンピューティング(RC)※1は、入力層、レザバー層、出力層で構成される、再帰型ニューラルネットワーク(RNN)の一種であり、時系列データに対するエッジAIを実現するAIモデルとして期待されています。レザバー層は、ニューラルネットワーク以外にも多様な力学系で構築が可能なため、物理実装※2と呼ばれる新しい仕組みによるハードウェア上での情報処理が可能です。この物理実装は、CPUやGPUなどの既存の計算機よりも極めて高いエネルギー効率性を示すため、エッジAIを実現するための鍵と考えられています。一方で、RCは学習される重みが出力層のみに限定されるため、最先端のRNNモデルに比べて学習性能が劣る欠点を持ちます。すなわち、エッジAIの実現のために、高いエネルギー効率を実現する物実装性と、高い学習性能とを両立するAIモデルが求められています。
■ 内容
本研究では、RCの学習性能の向上を目指し、RCに神経修飾機構を模した自己制御機能を付与する拡張を行い、RCの学習性能を飛躍的に向上させることに成功しました。この新しいモデルを自己制御型レザバーコンピューティング(Sel-modulated RC: SM-RC)と名付けました。
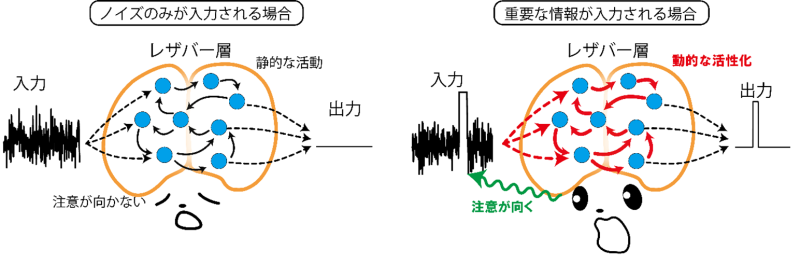
RCは、入力信号を高次元空間であるレザバー層に伝達させることで、出力層のみの学習に限定しても高い学習性能を示します。一方で、入力信号のレザバー層への伝達の仕方は、入力信号のダイナミクスに依らず一定であるため、レザバー層内でのダイナミクスは多様性に欠けます。実際、RCにおいては、入力強度とレザバー層の内部結合強度(スペクトル半径)は、タスクに応じて精密に調整する必要があります。そこで、私たちは、入力に依存して情報処理を大きく変化させる機構である注意機構に着目しました。注意機構は、深層学習においても重要視されており、また神経科学おいては、神経修飾機構が注意機構に大きく関わっていると考えられています。神経修飾機構とは、ある脳領域のニューロンが神経修飾物質を別の脳領域に投射することで、その領域の神経活動を変調する機構です。私たちは、この神経修飾機構を模した機構をRCに導入し、SM-RCを考案しました。図1に示すように、SM-RCは、入力ゲートとレザバーゲートを持ち、入力強度とスペクトル半径を、それぞれ変調することができます。これらのゲートはレザバー層からの出力によって動的に制御されるため、入力信号に依存した適応的な複雑なダイナミクスをレザバー層内に引き起こすことができます。
従来式のRCとSM-RCの動作の違いを明確に示すために、単純アテンションタスクを用いて、学習結果の比較を行いました(図2)。単純アテンションタスクでは、入力信号をレザバー層内に保持しているときに、入力ノイズがレザバー層をかき乱してしまうため、従来のRCでは解くことが困難でした。一方で、SM-RCでは、入力信号を保持しているときは、入力ゲートを閉じることでノイズの影響を抑え、さらにスペクトル半径を大きくすることで情報の保持を実現しています。さらに、興味深いことに、この情報保持の間は、レザバー層はカオス状態にあることがわかりました。従来のRCはカオス状態では学習が困難であることが知られていますが、 SM-RCではカオス状態も有効に活用していることがわかります。このように、SM-RCは、従来のRCでは実現不可能な複雑なダイナミクスをレザバー層内に引き起こすことで、学習性能を向上させていることがわかりました。
SM-RCは、一般的な時系列予測ベンチマークの一つであるカオス時系列予測タスクにおいても高い予測性能を持つことがわかりました。図3にカオス時系列予測タスクに関して、他のRNNモデルと性能比較した結果を載せています。RCの学習性能はレザバー層のサイズを大きくすることで向上することが知られていますが、SM-RCは10分の1のサイズのレザバー層で、従来式のRCと同様の予測性能を示すことがわかりました(図3(a))。また同様に、RCを含むRNNモデルは学習パラメータ数を増やすと予測性能が向上することが知られています。SM-RCは、同じ学習パラメータ数において、従来式のRCよりも学習性能が高く、さらに、LSTM、GRUなどの最先端のRNNモデルと同様の学習性能を持つことがわかりました(図3(b)。
SM-RCは高い学習性能を持つだけではなく、従来式のRCと同様物理実装性にも優れていると考えられます。それはSM-RCでは、一つのゲート機構によって、ネットワーク全体を均一的に動的制御するからです。この特徴により、精密に制御ができないような力学系においても物理実装を可能にします。一方で、LSTMやGRUは、一つ一つのニューロンに対して個別のゲート機構が存在します。そのため、精密な制御が必要となり物理実装が困難になります。なお、SM-RCは出力層以外も学習するので、RCが持っていた高速な学習性は失われています。以上の性質から、表1に示すように、SM-RCはRCと最先端のRNNモデルの中間的な役割を有すると考えられます。そして、これらのモデルの中で、唯一SM-RCが、高いエネルギー効率を実現する物理実装性と高い学習性能とを両立していることがわかります。
本研究では、数値シミュレーションによるSM-RCの学習性能の検討にとどまっており、社会実装のためには、SM-RCの物理実装まで踏み込む必要があります。今後は、SM-RCの具体的な物理実装形態やハードウェア上での学習の仕組みなど、ハードウェア化に関する研究を進めてまいります。
※1) レザバーコンピューティング (RC)
入力層、レザバー層、出力層で構成される再帰型ニューラルネットワーク(RNN)の一種。典型的にはレザバー層はランダム結合のRNNで実装されるが、様々な力学系を用いることが可能です。この性質により、様々な形態での物理実装が進められています。また、レザバー層と出力層の間の結合のみを学習するため高速な学習が可能です。
※2) 物理実装
物理実装は、半導体、フォトニクス、スピントロニクスなどを用いることで計算機システムを構築することであり、デジタルシステムとは異なり、物理法則を直接的に演算の基礎とする特徴があります。物理実装は、非常に高速かつ高いエネルギー効率を示しますが、その複雑性のため大規模システムの構築が困難です。RCは様々な力学系を用いることが可能なため、物理実装に適していると考えられています。
■ 論文情報
雑誌名: Communications Physics
論文題目: Learning Reservoir Dynamics with Temporal Self-Modulation
著者: Yusuke Sakemi、Sou Nobukawa、Toshitaka Matsuki、Takashi Morie、and Kazuyuki Aihara
URL: https://www.nature.com/articles/s42005-023-01500-w
DOI: 10.1038/s42005-023-01500-w
発表日時: 2024年1月12日
■ 謝辞
本研究の一部は、JSTさきがけJPMJPR22C5、セコム科学技術振興財団、JST Moonshot R&D Grant Number JPMJMS2021、AMED under Grant Number JP23dm0307009、the International Research Center for Neurointelligence (WPI-IRCN) at The University of Tokyo Institutes for Advanced Study (UTIAS)、JSPS KAKENHI Grant Number JP20H05921から助成を受けて行われました。
<お問い合わせ先>
千葉工業大学 数理工学研究センター 上席研究員
酒見 悠介
【取材・大学広報関連に関する問い合わせ先】
千葉工業大学 入試広報部
大橋 慶子
■ 添付資料
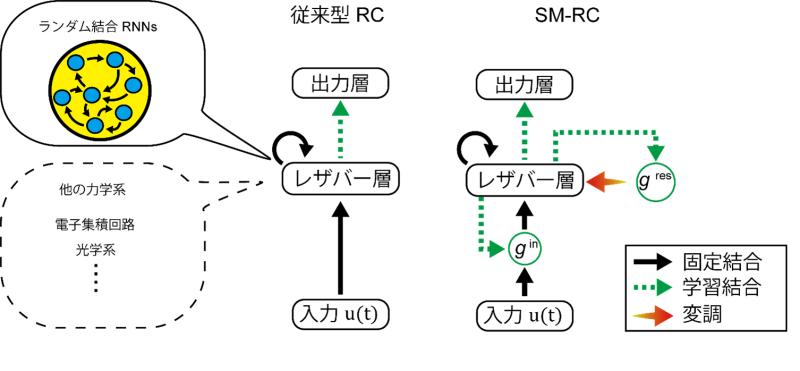
図1 従来型のRCと提案したSM-RCの構造の比較
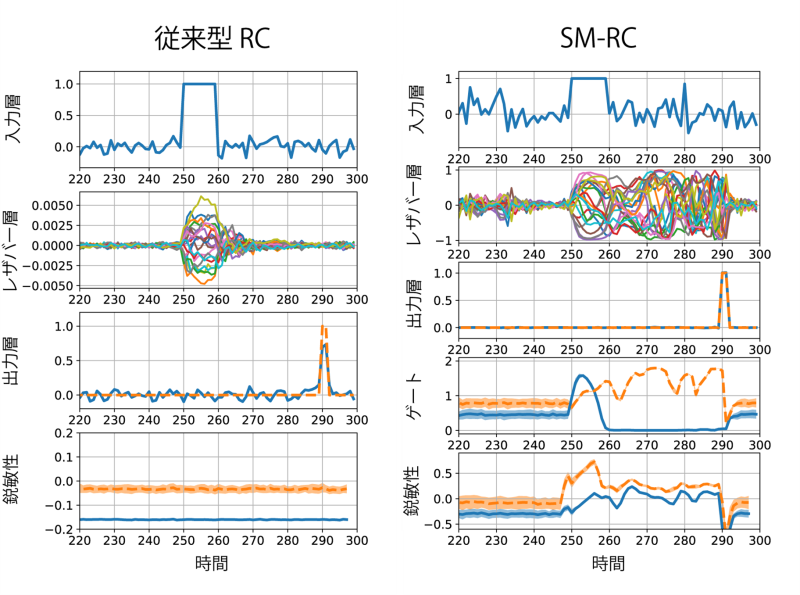
図2 単純アテンションタスクにおける従来型RCとSM-RCの動作比較
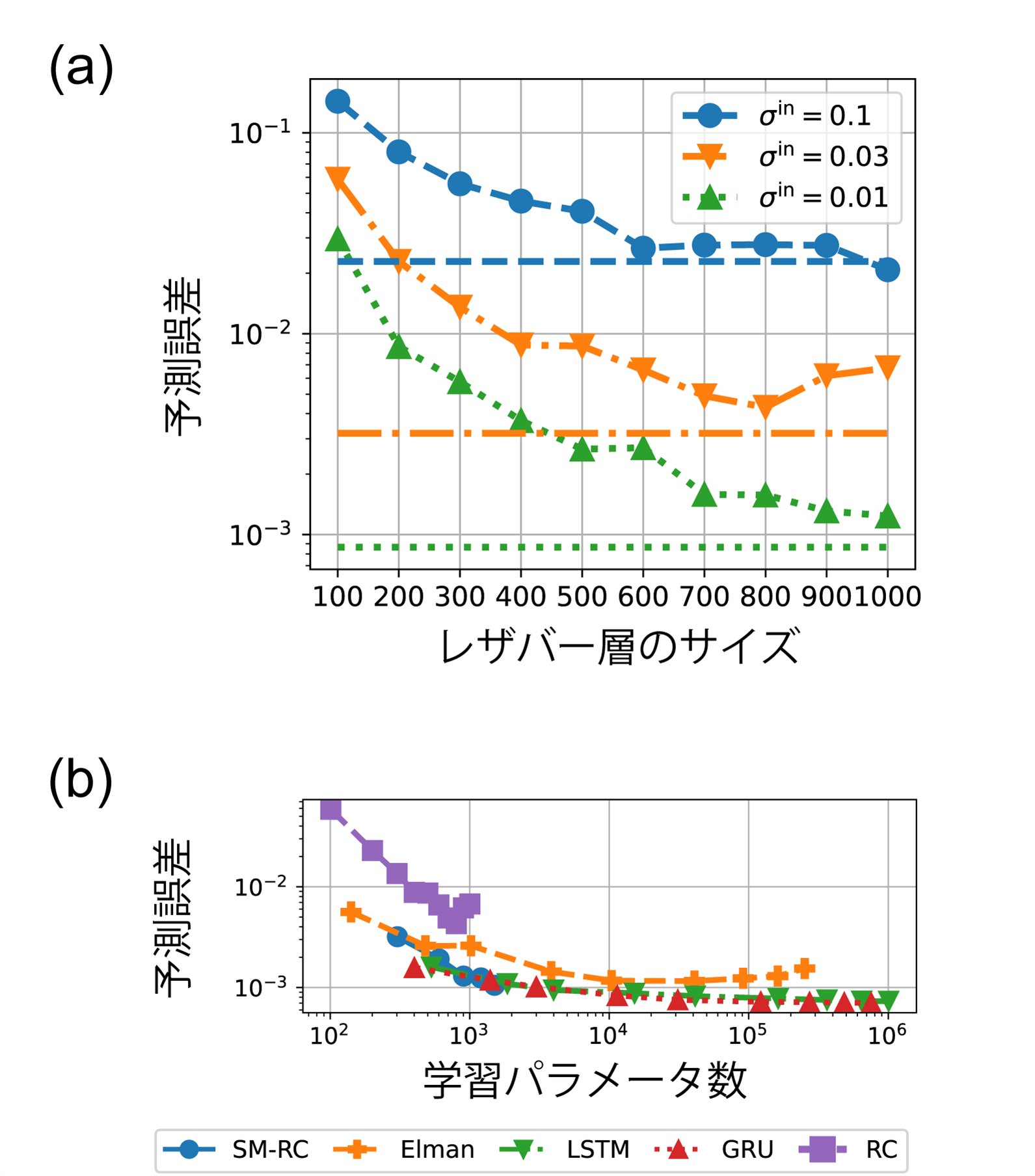
図3 カオス時系列予測の学習性能比較
表1 各種RNNモデルの比較



