Accurate prediction of natural phenomena based on real world data, from molecules to brain activity, stock markets and weather, is one of the great challenges of science and society. If mathematical science could devise better methods for prediction it could revolutionize our understanding of the world. However, data collected from real world measurements often suffer from the so-called Curse of Dimensionality, a term coined by the late mathematician Richard Bellman to describe the difficulty in reducing a complex system from its many variables or measurements, known as high-dimensional data, into simpler terms that are more useful for making powerful and precise predictions.
Now in a study published in the Proceedings of the National Academy of Sciences in October 2018 an international research team has discovered a possible route to not only battle the Curse of high-dimensional data but to turn it into an advantage for making predictions. The group, led by Luonan Chen of the Chinese Academy of Sciences, Wei Lin of Fudan University and Kazuyuki Aihara of The University of Tokyo International Research Center for Neurointelligence (IRCN), used a method called randomly distributed embedding (RDE) to create a novel procedure for reducing high-dimensional data into simple lower dimensions that can more easily be transformed into statistical distributions for generation of more accurate predictions.
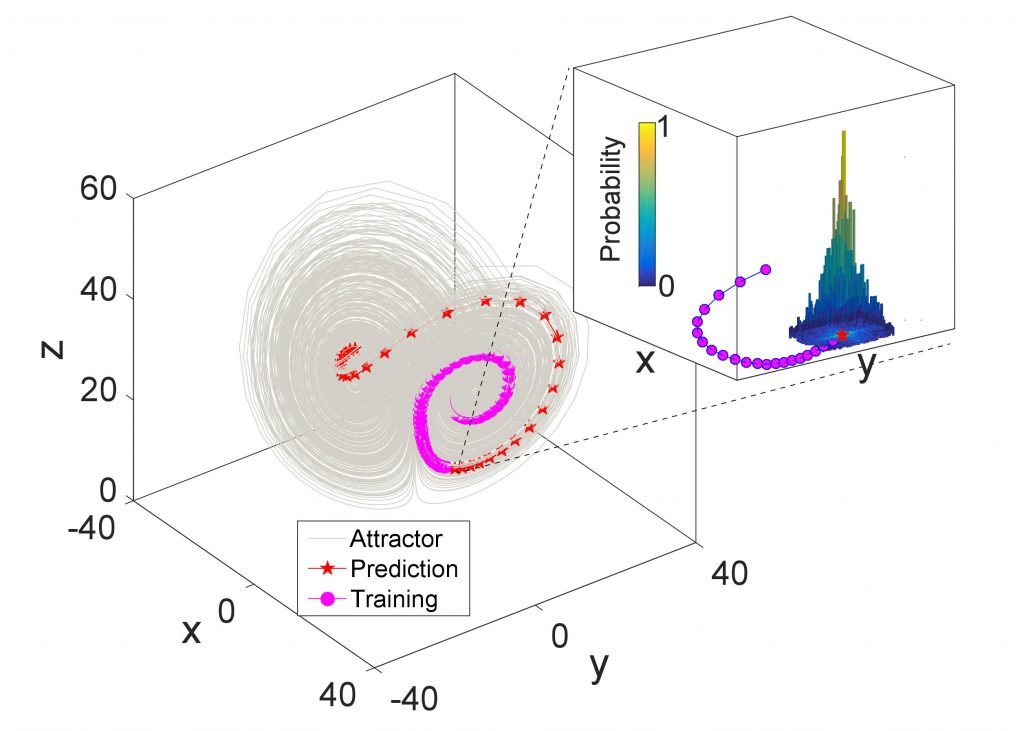
RDE is based on a mathematical equation that connects the past history of high-dimensional data to the future dynamics of target variables. Thus, solving this equation means predicting the future from a mathematical and dynamical viewpoint. To test this conjecture, the authors transformed short temporal strings of high-dimensional data into two distinct representations of low-dimensional data; one for the long time components of a small number of variables and the other the high-dimensional short time space components. The time and space representations were mapped onto each other to generate a rich dataset that could create a probability distribution for their target variables. They tested the model on real world datasets including the expression level of different genes in the liver, wind speeds across Tokyo, and the relation between pollution levels and hospital admissions.
The computer algorithm provided good prediction of these natural phenomena suggesting that further improvements could lead to better forecasting power for other big datasets. In the future, the authors hope to apply random embedding methods to the fusion of human and machine intelligence, a new field called neurointelligence. For example, predicting brain activity, a low-dimensional data, from behavior, a high-dimensional data, could enable the design of neurofeedback prosthetics that could adjust neural activity to treat symptoms of brain diseases. While such speculation remains to be examined experimentally, the new work shows that there is hope to overcome the problems associated with the analysis of real world big data.
The use of randomly distributed embedding (RDE) may point toward novel forms of artificial intelligence. As a learning or training process, solving the RDE equation can be viewed as a “wide-learning” algorithm involving small sample sizes and high-dimensional data. This approach contrasts with current “deep-learning” algorithms that require large sample sizes. The authors speculate that the RDE equation may be a mathematical description of human neural networks, since learning to predict future events based on past information, as occurs in pattern recognition, is a key feature of cognition, and may help to pioneer methods to study brain intelligence.
Correspondent: Charles Yokoyama, Ph.D., IRCN Science Writing Core
Reference: Ma, H., Leng, S., Aihara, K., Lin, W., and Chen, L. (2018) Randomly distributed embedding making short term high-dimensional data predictable. Proc. Natl. Acad. Sci. USA 115:43, Published online: October 8, 2018. DOI: 10.1073/pnas.1802987115
Media Contact: The author is available for interviews in English.
Professor Kazuyuki Aihara, Ph.D.
Institute of Industrial Science
International Research Center for Neurointelligence
The University of Tokyo
Mayuki Satake
Public Relations
International Research Center for Neurointelligence
The University of Tokyo
satake.mayuki@mail.u-tokyo.ac.jp


