In the animal kingdom, adaptive behavior is essential for survival and reproduction. In particular, vertebrates including humans, mammals, birds and other classes have brains that evolved for the exploitation or avoidance, respectively, of rewards and risks in their local environment. These brains contain a neuronal reward system using the chemical transmitter dopamine that helps an animal to process risk and reward information in the form of pulses and dips in dopamine levels. In recent years, neuroscientists have begun to understand the rules governing dopamine’s actions in reward learning and in a related theoretical model called reinforcement learning. Recently, two studies from a team of researchers based at the International Research Center for Neurointelligence have leveraged current biological knowledge on the dopamine system to develop computational models at both molecular and behavioral levels that may inspire novel AI.
The first study (1) examined the intracellular molecular machinery that shuttles dopamine signals from cell receptors to changes in specialized cell compartments called postsynaptic spines, the small protrusions on cell dendrites that enable intercellular communication. In a deep brain area called the ventral striatum reside two types of cells with dopamine receptors, called D1 and D2 that handle, respectively, reward and risk (or punishment) learning. The researchers built a detailed molecular model of the protein cascade that resides in D1 and D2 cells (Figure 1). D1 and D2 cells learn the language, so to speak, of dopamine pulses and dips, respectively, to enlarge their spines in the form of memory. Interestingly, the model reveals the role of a protein enzyme called adenylyl cyclase type 1 in “contingency detection” where two signals arrive on a single cell in the same time window, allowing the cell to learn what the researchers call “temporal contiguity” or the pattern of dopamine in reward learning.
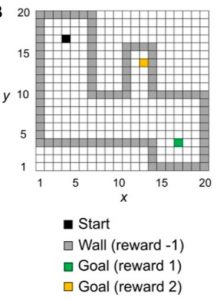
In the second study (2), the team zoomed out to the animal behavioral level by developing a model of reinforcement learning that has D1-like and D2-like cells in a multilayered neural network designed after a form of network configuration called an extreme learning machine (ELM). The model, called OVaRLAP, contains computational elements similar to the D1 and D2 neurons that are known to process respective positive or negative dopamine reward prediction error signals. These distinct signals are thought to drive two different patterns of reinforcement learning, generalization and discrimination, that were recently validated by the group in Iino et al. (2020) Nature. The team tested the performance of OVaRLAP against a computer game called the painful grid world navigation task where the agent controlled by the model has to avoid the “painful” walls of a maze to move to safety (Figure 2).
OVaRLAP showed high performance due to a fast generalization resulting from the D1- and D2-like elements in the network’s final layer. However, in a similar game played with impairment in discrimination learning by D2-like elements and background noise applied to the ELM, the model surprisingly failed to generate proper behavior. The authors suggest this aberrant behavior might mimic mental conditions such as schizophrenia related to the intrinsic design of the dopamine reward system and its powerful generalization and discrimination capacity, where high performance is associated with a higher risk of system breakdown. Intriguingly, the results imply that future neuro-inspired AI might inherit both high cognitive capacity and mental disorders from their biological antecedents, a cautionary note. Together, the two studies show that multiscale modeling, from molecules to behavior, can reveal insights not only on dopamine reward learning but on the human brain itself.
Correspondent: Charles Yokoyama, Ph.D., IRCN Science Writing Core
Reference 1: Urakubo, H., Yagishita, S., Kasai, H., Ishii, S. (2020) Signaling Models for Dopamine-dependent Temporal Contiguity in Striatal Synaptic Plasticity. PLOS Comp. Biol. 16(7):e1008078, Published online: July 23, 2020. DOI: 10.1371/journal.pcbi.1008078
Reference 2: Fujita, Y., Yagishita, S., Kasai, H., Ishii, S. (2020) Computational Characteristics of the Striatal Dopamine System Described by Reinforcement Learning with Fast Generalization. Front. Comp. Neurosci. 14(66), Published online July 22, 2020, DOI: 10.3389/fncom.2020.00066
Figure 1 (Reference 1): Intracellular signaling cascade for reinforcement plasticity via spine volume changes in dopamine receptor 1 spiny projection neurons of mammalian striatum.

Figure 2 (reference 2): Grid world navigation task used to examine the performance of OVaRLAP, a dopamine-based reinforcement learning algorithm with fast generalization.
Media Contact: The author is available for interviews in English.
Professor Shin Ishii, Ph.D.
International Research Center for Neurointelligence (IRCN)
Graduate School of Informatics, Kyoto University
Professor Haruo Kasai, M.D., Ph.D.
International Research Center for Neurointelligence (IRCN)
The University of Tokyo Institutes for Advanced Study
Mayuki Satake
Public Relations
International Research Center for Neurointelligence (IRCN)
The University of Tokyo Institutes for Advanced Study
pr@ircn.jp


